IT之家8月23日消息,科技媒体9to5Mac今天发布博文,报道称苹果研究团队开源SlowFast-LLaVA-1.5长视频多模态大语言模型,在1B、3B、7B参数规模下,均刷新LongVideoBench、MLVU等SOTA基准纪录。
IT之家援引博文介绍,当前大语言模型在处理和理解视频方面,通用做法是在AI预训练中集成视频感知,但这种做法存在以下3重局限性:
苹果公司针对上述3个局限性,首先研究推出了SlowFast-LLaVA开源模型,最大的亮点是创新双流(two-stream)设置,其中“慢流”选取少量高分辨率帧捕捉场景细节,“快流”选取更多低分辨率帧追踪运动变化。
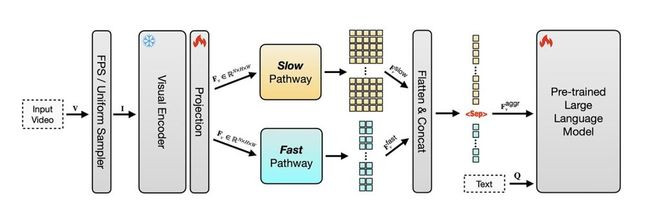
苹果进一步在开源模型SlowFast-LLaVA模型上,通过微调图像模型,进一步增强视觉推理能力,再联合图像与视频训练,保留图像理解优势,推出了SlowFast-LLaVA-1.5版本。
在设计上,SF-LLaVA-1.5将输入视频帧数固定为128,其中快流96帧,慢流32帧,适配各种时长视频。这种方法虽可能漏掉关键帧或影响播放速度判断,但显著降低了计算和显存需求。研究团队指出,可通过引入内存优化技术(如随机反向传播)进一步改进,但需解决高显存占用问题。
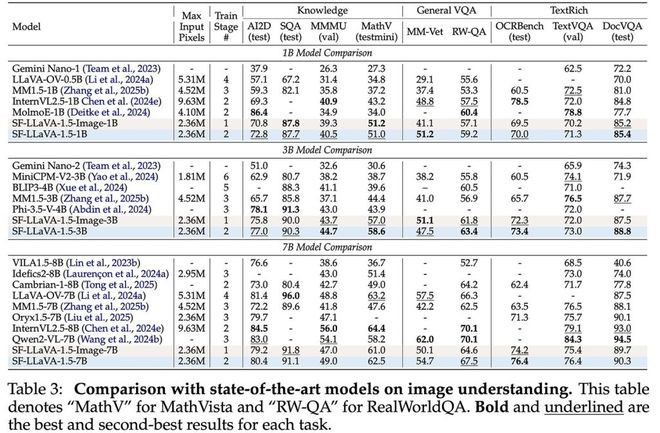
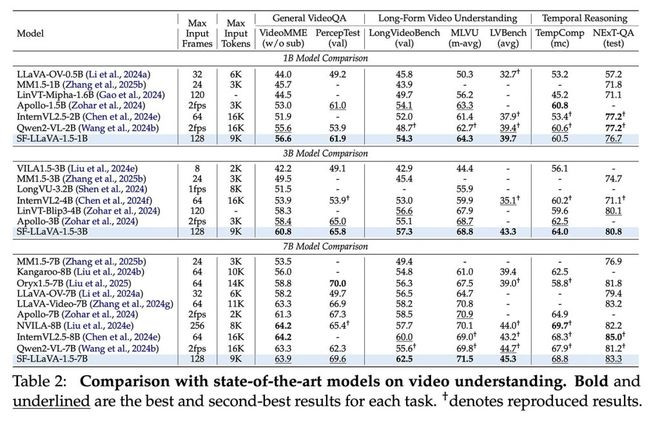
测试显示,该模型在长视频基准LongVideoBench、MLVU上均取得新纪录,而且1B版本也能领先竞争对手。同时,它在知识问答、数学推理、OCR等图像相关任务上表现出色,实现视频与图像的通用理解能力。
该项目完全基于公开数据集训练,方便学术与产业复现,并已在GitHub与HuggingFace开源。




“寻龙点穴”通俗来讲,就是为阴宅(墓地)或阳宅(地基)寻找一个能汇聚天地生气的理...
4月9日,MiniMax宣布发布一个面向AIAgent的命令行工具——MMX-C...
【摩根大通:中美贸易关系取得进展后美元或落后美股】金十数据5月13日讯,摩根大通...
2025年2月28日,广东省精准医学应用学会第二届会员代表大会第三次会议在广州召...



 QQ:
QQ:

 返回顶部
返回顶部